
Sandboxing: the sweet spot between autonomy and security
Fully locking down an AI coding agent makes it useless. Giving it unconstrained access makes it dangerous. Sandboxing is the answer.
The Fundamental Tension
AI coding agents' biggest value is their ability to act autonomously: executing commands, installing packages, calling APIs, and opening pull requests. Yet this same capability introduces significant security risks. The core challenge lies in determining how much freedom an agent can have before the potential dangers become unacceptable.
Two Failure Modes
Over-Restriction
Completely restricting an AI coding agent (like denying network access, enforcing read-only filesystems, and prohibiting package installations) makes it incapable of performing real-world tasks. Without the ability to run tests, install dependencies, or clone repositories, the agent becomes little more than a sophisticated wrapper around a basic language model, offering no practical utility. This approach isn't a security solution, it's a method of running simple LLMs with limited "agent" capabilities.
Unrestricted Execution
Granting an AI coding agent full access to a developer's or employee's machine maximizes its capabilities but also its dangers. A single prompt injection or compromised package could lead to catastrophic consequences, exposing the entire system to risk. In this scenario, the agent's power becomes its greatest weakness, with one vulnerability potentially granting full blast radius to attackers.
This is not theoretical. The IDEsaster research uncovered 24 CVEs across major AI coding tools including Cursor, GitHub Copilot, Claude Code, and Windsurf. Simon Willison describes the core problem as the "Lethal Trifecta": when an agent has access to private data, is exposed to untrusted content, and can communicate externally, an attacker can trick it into exfiltrating sensitive information.
For a deeper dive into these risks, particularly the sections on prompt injection and remote code execution:
What Sandboxing Actually Means
Sandboxing provides a balanced approach through multiple layers of isolation and control. Here's what it entails:
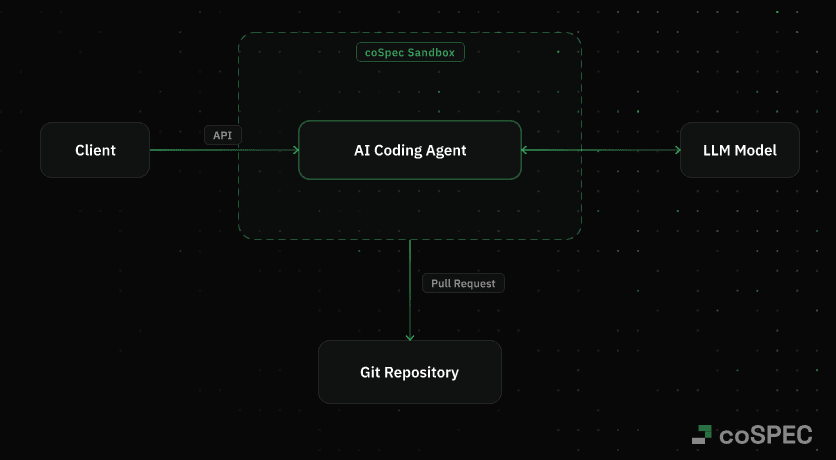
Filesystem Isolation
Each agent run operates within its own dedicated filesystem, completely isolated from the host system and other runs. This environment is fully discarded after the run completes, ensuring no changes persist and no data is visible or accessible.
Technologies like gVisor take this further by reimplementing the Linux kernel interface in user space. No system call is passed directly to the host kernel. Google uses gVisor in their own GKE Agent Sandbox, built specifically for running AI agent workloads on Kubernetes.
Network Control
Network access is tightly controlled through domain allowlists and managed egress policies. This goes beyond basic firewall rules, precisely regulating which external services the agent can reach and under what conditions.
This directly breaks the attack chain Willison describes: even if an attacker manages to inject instructions via prompt injection, the agent cannot send data anywhere outside the allowlist. Without outbound communication to attacker-controlled endpoints, exfiltration attempts fail silently.
Time and Cost Limits
Hard limits on execution time and resource consumption are enforced at the infrastructure level. Unlike soft CLI flags, these cannot be bypassed and ensure runs terminate automatically when predefined boundaries (like maximum accepted cost) are exceeded.
Audit Trail
Every action taken by the agent is logged in a structured format, creating a comprehensive AI agent audit trail for post-mortem analysis, debugging, and compliance.
Why This Is the Sweet Spot
The key insight of sandboxing is that risks stem from escape and persistence, not from actions within a controlled environment. By addressing specific threat vectors directly:
- Remote Code Execution is contained through isolated environments that are discarded after each run.
- Prompt Injection, the #1 risk in OWASP's Top 10 for LLM Applications, is limited by network allowlists that prevent the agent from communicating with attacker-controlled endpoints.
- Supply Chain Attacks are neutralized as malicious packages have no avenues for data transmission outside the sandbox. This matters: the 2026 Sonatype report found over 454,000 new malicious packages published in 2025 alone, a 75% year-over-year increase.
- Data Exfiltration is prevented through egress controls that only allow connections to pre-approved endpoints.
The pattern is consistent: sandboxing does not prevent the agent from working, it prevents the consequences of failure from escaping the controlled environment. Meaningful autonomy within hard, enforceable limits.
Real-World Examples
Several companies are already running sandboxed AI coding agents in production at scale:
Spotify's Background Agent
Spotify's background coding agent operates within a sandboxed environment featuring network controls and cost limits. The results speak for themselves: over 1,500 merged pull requests, 650+ agent-generated PRs per month, and 60-90% time savings on code migrations. For more details, see Spotify's Background Coding Agent, Part 1.
Ramp's Background Agent
Ramp's background agent accounts for more than 30% of their merged pull requests. Each session runs in a sandboxed VM with a full isolated dev stack (Postgres, Redis, Temporal) with no contention between sessions and no load on developer machines. Learn more in Why We Built Our Background Agent.
coSPEC's Solution
coSPEC provides sandboxed execution environments designed for any agent workflow. Every run gets its own gVisor-isolated sandbox with network egress policies, cost limits, and a full audit trail, discarded completely after execution. Anthropic's own engineering team found that sandboxing reduces permission prompts by 84% while increasing safety, which aligns with the core premise: sandboxing makes agents both more useful and more secure.
For additional insights into how teams are implementing sandboxed agents in production:
The Right Approach to AI Security
People usually ask "how much do we trust the model?" The problem with this question is that it frames security as a binary choice: either you trust the model and give it full access, or you don't and restrict it to the point of uselessness. The reality is that security is not about trusting the model, it's about controlling the environment in which the model operates.
As NVIDIA's AI Red Team puts it: "AI-generated code must be treated as untrusted output, and sandboxing is essential to contain its execution." Application-level filtering creates a false sense of security. OS-level isolation is required.
Instead, focus on "what does the agent need, and what should be blocked?" An approach that starts with restrictions leads to useless agents. Prioritizing capabilities while enforcing clear boundaries creates tools that are both useful and safe. Teams that run agents effectively in production have built infrastructure that makes complete trust in the underlying model less critical, shifting the focus from model reliability to environmental controls.
FAQ
What is sandboxing for AI agents?
How do you secure AI coding agents?
Is AI-generated code safe to run in production?
gVisor Security Architecture · Google
Agentic AI on Kubernetes and GKE · Google Cloud
The Lethal Trifecta for AI Agents · Simon Willison
IDEsaster: 30+ Vulnerabilities in AI Coding Tools · The Hacker News
OWASP Top 10 for LLM Applications · OWASP
2026 State of the Software Supply Chain · Sonatype
How Code Execution Drives Key Risks in Agentic AI Systems · NVIDIA
Claude Code Sandboxing · Anthropic Engineering
Snyk AI Code Security Report · Snyk
Spotify's Background Coding Agent, Part 1 · Spotify Engineering
Ready to get started?